AUC-ROC Curve: A Comprehensive Guide to Model Selection in Machine Learning
I am a data scientist who loves building AI products that drive business success and productivity.
I am currently on the lookout for internship opportunities.
I am ready for collaboration anytime.
Introduction
There are a few Machine Learning (ML) algorithms to choose from when building an ML model. Different ML algorithms perform differently on the same dataset due to differences in algorithm complexity, bias-variance tradeoff, nature of data, feature interactions, etc. Developing an ML model is just the beginning; the key is to select the one that delivers the best performance on your dataset from the many available options, ensuring the success of your project.
This begs the question, how do you know which ML algorithm is best for your dataset? It is by evaluating and comparing the performance of the different ML models using the AUC-ROC curve.
AUC-ROC Curve
AUC-ROC stands for “Area Under the Curve” of the “Receiver Operating Characteristic”. AUC-ROC curve is a common way of visualizing the performance of a binary classifier, i.e., a classifier with two possible output classes. With a little tweak, you can use it to visualize the performance of a multi-class classifier, i.e., a classifier with more than two possible output classes.

Image Source:
In this article, you will learn the following:
what an AUC-ROC curve is,
its importance and
Implement the AUC-ROC curve with Sklearn in Python.
Make sure to read to the end.
ROC Curve
An ROC curve plots the True Positive Rate (TPR) on the y-axis, versus the False Positive Rate on the x-axis for every possible classification threshold. The classification threshold is the value that determines the cutoff point at which a model classifies a predicted probability as either positive or negative. It can range between 0.0 and 1.0.
TPR: This is also called Recall or Sensitivity. It is the ratio of the positive classification (True Positive) made by the model to the actual positive class (both True Positives and False Negatives):
TPR answers how often the classifier predicts positive when the classification is positive.
FPR: This is the ratio of incorrectly classified positives (False Positives) to the total number of actual negatives (both True Negatives and False Positives):
FPR answers how often a classifier predicts a positive class when the classification is negative.
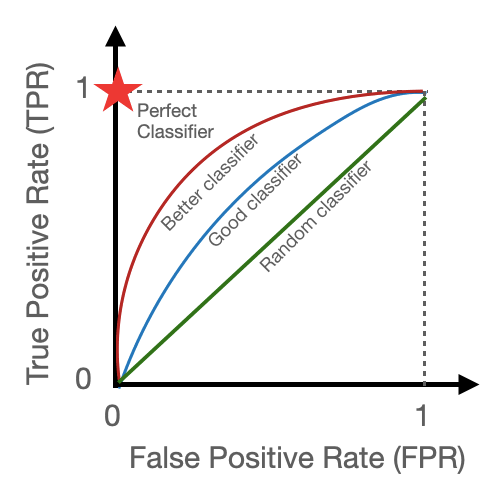
Figure 2
The ROC figure above reveals the performance of four different classifiers across different possible thresholds. From the ROC figure, you can make the following interpretation:
The scale for a ROC curve ranges from zero to one on both the x and y-axis. The ideal score for TPR on the scale is one, and zero for FPR.
The Perfect Classifier, indicated by a red star has a TPR of 1 (100% TPR) and an FPR of 0 (0% FPR). This classifier is perfectly able to separate the positive and negative classes.
The Random classifier has a TPR of 1 and a FPR of 1. The green diagonal line represents a classifier equivalent to a random guessing. It cannot be trusted to make accurate predictions.
The Better and Good Classifier represents models with decent performances. They achieved a balance between the TPR and FPR.
The Classifier with the Red curve is better because it is closer to the top-left corner of the plot. It indicates better performance at any given threshold compared to the Good Classifier.
A perfect classifier has a point close to the top left corner of the ROC curve.
AUC
Connecting the points forms the ROC curve, which creates a trapezoidal shape along the x and y axes. The AUC calculates the area under the ROC curve, which is trapezoidal, and returns a single summary statistic of the ROC curve.
The AUC computes the area under the ROC curve. It measures the ability of a model to distinguish accurately between the classes using a single metric. The AUC ranges between 0.0 and 1.0.
When AUC = 1, it shows that the classifier can accurately differentiate between all the Positive and Negative classes. This is an excellent classifier
If AUC = 0, the classifier would predict all Positive classes as Negatives, and all Negative classes as Positives.
If AUC = 0.5, then the classifier makes a random classification.
If AUC > 0.5 but < 1, then the classifier can accurately predict more Positive classes than Negative classes. It can detect more TP and TN than FN and FP. A model with an AUC closest to 1.0 is desirable among the rest.
AUC-ROC curve True Positives
Unlike other evaluation metrics like Accuracy, F1 score, and AUC-ROC curve ultimately
help you to select the best model for your project among the other options
help you choose the optimal threshold for assigning labels using Youden’s J Statistic, depending on if you are trying to reduce the False Positives or False Negatives
are useful for evaluating models on an imbalanced dataset where accuracy or F1-score can be misleading
Implementation
Now we are going to implement this using the Scikit-learn library in Python.
The prerequisites for implementing the AUC-ROC in Python with Scikit-learn are:
Data Cleaning
Exploratory Data Analysis
Feature Engineering
Feature Selection
Let’s jump into model training and evaluation using the AUC ROC curve.
For your convenience, here’s the direct link to the dataset used for the implementation in this article: Airline Satisfaction Dataset. The dataset contains customer feedback on various contexts of their flight with the airline, which can be used to predict whether a future customer will be satisfied with their service.
In this implementation, we will use five different ML classification algorithms: AdaBoost, Gradient Boosting, Random Forest, Logistic Regression, and Decision Tree.
Import necessary libraries
# import libraries for ROC curve
import numpy as np
from sklearn.metrics import roc_curve, auc
# Importing different classifiers from Scikit-learn
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import AdaBoostClassifier, GradientBoostingClassifier, RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
This code imports the necessary libraries and classifiers for generating a ROC curve and evaluating machine learning models.
Numpy: For numerical operations (imported as
np).roc_curve, auc: Functions from
sklearn.metricsthat calculate the ROC curve and area under the curve (AUC).LogisticRegression, AdaBoostClassifier, GradientBoostingClassifier, RandomForestClassifier, DecisionTreeClassifier: Five different classifiers from Scikit-learn, which will be used for model training and evaluation.
Storing and Intializing the models
# Initialize the models
models = {
'Logistic Regression': LogisticRegression(),
'AdaBoost': AdaBoostClassifier(),
'Gradient Boosting': GradientBoostingClassifier(),
'Decision Tree': DecisionTreeClassifier(),
'Random Forest': RandomForestClassifier()
}
- The multiple models were initialized inside a Python dictionary, to make it organized, easy, and available for iteration in training, prediction, and evaluation.
Model training, prediction, and calculation
for model_name, model in models.items():
# Fit model
model.fit(X_train, y_train_encoded)
# Predict probabilities
y_probs = model.predict_proba(X_test)[:, 1]
# Calculate ROC curve
fpr, tpr, = roccurve(y_test_encoded, y_probs)
# Calculate AUC
roc_auc = auc(fpr, tpr)
# Plot ROC curve
plt.plot(fpr, tpr, lw=2, label=f'{model_name} (AUC = {roc_auc:.2f})
- The multiple models were trained on the training data. The model then makes prediction probabilities on the test data. FPR and TPR were calculated using the actual class and predicted probabilities.
Plotting the ROC curve
plt.figure(figsize=(10, 8))
# Plot diagonal line
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
# Customize plot
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc='lower right')
plt.grid(alpha=0.3)
plt.show()
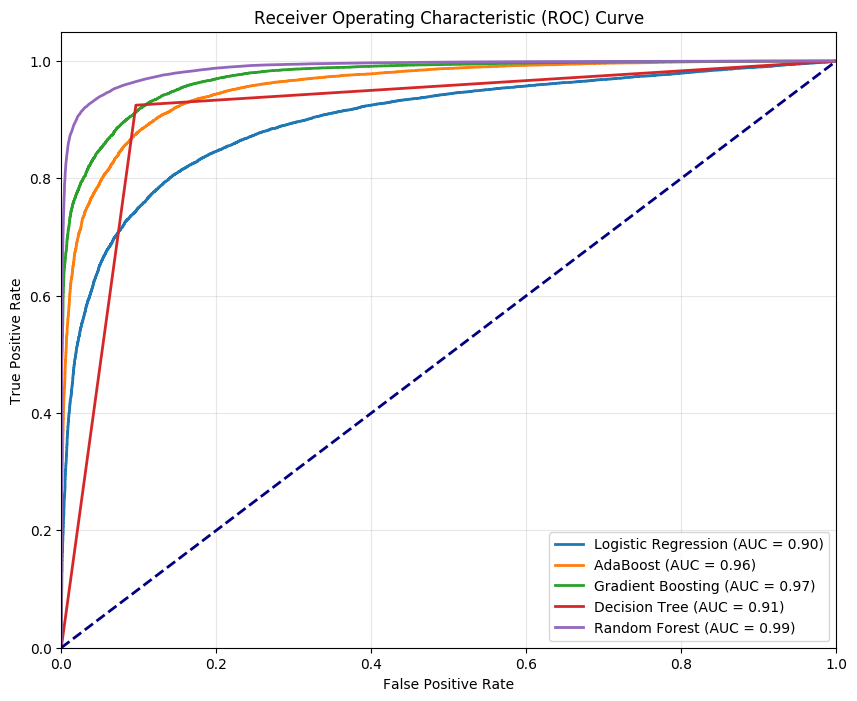
Figure 3: ROC curve
From the AUC ROC image above, you can make the following deductions:
All the models performed well on the Airline Customer Satisfaction dataset.
Random Forest classifier demonstrates the best performance among the five classifiers as it is the closest to the top-left corner. It has an AUC of 0.99.
It is followed closely by Gradient Boosting and AdaBoost. They have AUCs of 0.97 and 0.96 respectively. The model with the least performance is the Logistic Regression with an AUC of 0.90.
You are to select a Random Forest Classifier for your project.
Calculating the Optimal threshold
# y_test_encoded are the true labels and y_scores are the predicted probabilities
fpr, tpr, thresholds = roc_curve(y_test_encoded, y_probs)
# Calculate Youden's J statistic
J = tpr - fpr
optimal_idx = np.argmax(J)
optimal_threshold = thresholds[optimal_idx]
print(f'Optimal Threshold: {optimal_threshold}')
After selecting the best model for your project, you can use Youden’s J Statistic to calculate the optimal threshold for your model to make the classification. The optimal threshold after calculation, in this case, is 0.58
You can also select your threshold based on the domain, whether you want to minimize False negatives (medical diagnosis) or False positives (spam detection).
Conclusion
Machine learning is all about experimentation. It is an inherently iterative process. No single machine learning model is universally optimal for all use cases and projects in every situation. Selecting the most effective model for a given project is crucial for the project's success.
With the AUC-ROC curve, you can visually compare the performance of different ML models on a given dataset. Visualizing the trade-offs between TPR and FPR provides a more informed and objective way of selecting the best ML model for your project.
In this article, by utilizing the AUC-ROC curve, you’ve identified the best model (Random Forest) for your project and determined the optimal decision-making threshold (0.58) based on your dataset.
Complementary evaluation techniques like Precision, Recall, and F1-score should also be considered especially in scenarios involving imbalanced datasets.
